
Nebius Deep Dive: AWS of AI or a Bubble?
Understanding the AI infrastructure upstart targeting $7-9B ARR in 2026!

Welcome to Global Equity Briefing, my weekly investing newsletter.
I am Ray, a passionate investor and equity analyst. And today I am covering an extremely interesting AI infrastructure business.
We are currently in the midst of an AI boom, with many predicting that it will have a bigger impact on the economy and the stock market than electricity did!
Nvidia has been the poster child of this new AI revolution, as AI start-ups and cloud hyperscalers are spending hundreds of billions of dollars on GPUs.
While Nvidia became rich by selling AI picks and shovels, Nebius aims to become rich by being an AI refinery and processor.
In gold mining, after miners have used picks and shovels, before gold can be of any use, it must be refined and processed.
Similarly, raw GPU power (picks and shovels) is not enough. To deliver great AI services, companies need to refine AI to make it faster, more accurate, and cheaper.
This is what Nebius helps with.
In a sense, Nebius is hoping to become the AWS of AI!
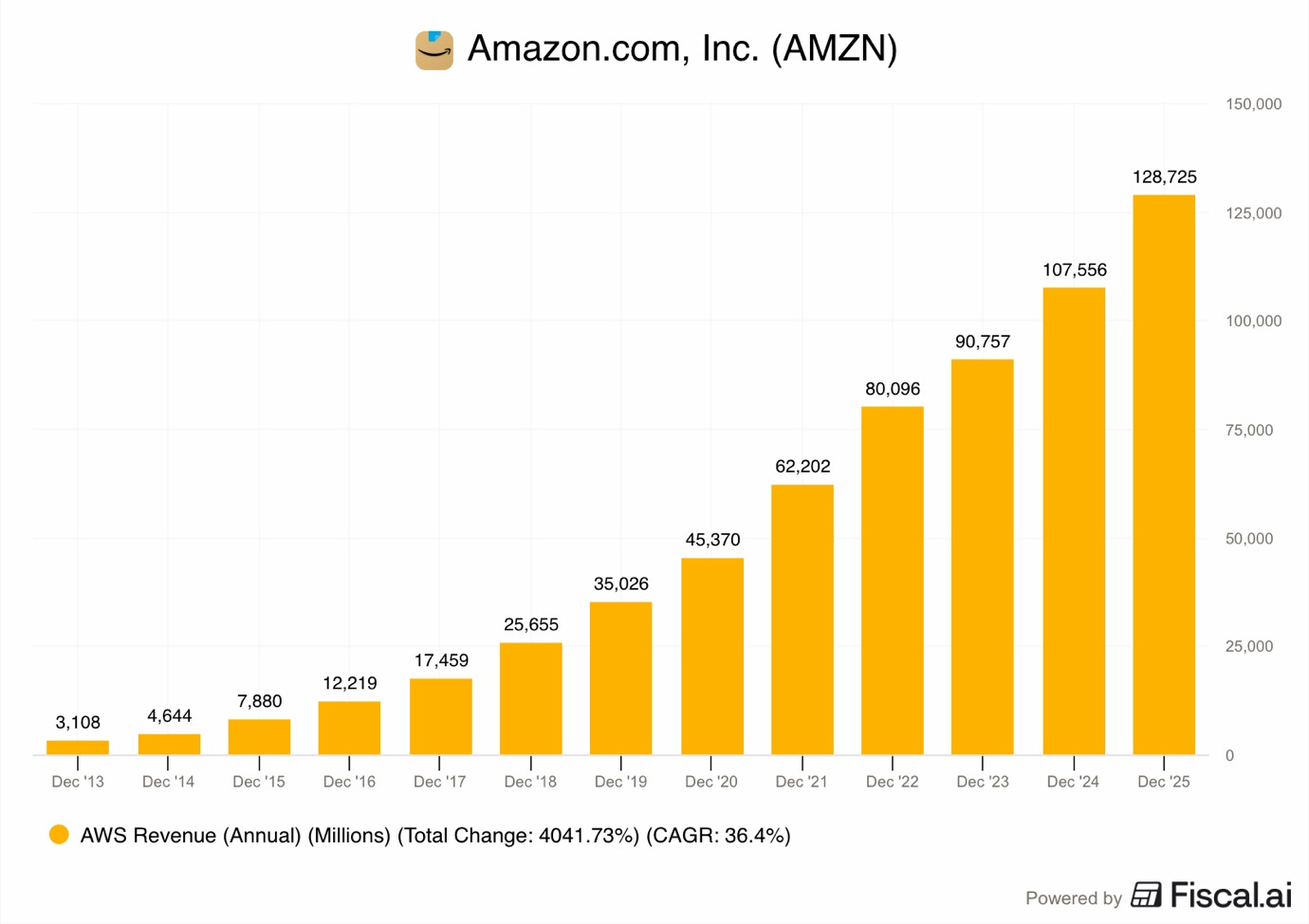
AWS became a $100B+ revenue business by riding the wave of global digitization. The company provided general-purpose cloud computing, enabling most of the 2010s tech success stories, such as Uber, Netflix, Airbnb, and Spotify, to scale without having to host expensive servers themselves.
Nebius wants to do the same by providing AI-ready cloud computing to the next generation of tech leaders, the newest and fastest-growing start-ups!
Known clients include fast-growing start-ups such as Higgsflied AI, Cursor, and Revolut, and Hyperscalers Microsoft and Meta.
If successful, Nebius could 100x their current business, becoming one of the largest tech companies in the world, making their shareholders extremely happy.
This is my longest Deep Dive to date, consisting of 60 pages and over 11,000 words.
In this Deep Dive, I will explain how Nebius plans to become one of the largest success stories of the current AI boom!
Let’s dig in.
1. Brief History
2. Business Model
3. AI Cloud
4. Data Centers
5. Customer Deals
6. Subsidiaries
7. Competitors
8. Risks
9. Opportunities
10. Valuation
11. Valuation Model
12. Conclusion
: Future Prospects and Stock Price Outlook - MiFsee")
1. Brief History

Yandex is one of Europe’s largest internet technology companies. It was founded in Russia in 1989 and became extremely popular, and is essentially Russia’s answer to Google.
In the 2010s, the company began expanding outside Russia and built various internet businesses in Europe and the US.
However, if you haven’t lived under a rock, you know that in 2022, Russia invaded Ukraine.
Yandex founder and CEO, Arkady Volozh, didn’t agree with this decision and openly spoke out against the invasion. Despite that, his company, Yandex Group, was put on the sanction list by the US, and thus it was delisted from the Nasdaq.
Shortly after, in part due to pressure and in part from his own desire, he sold all of Yandex’s core Russian assets for about $5.4B and kept the foreign assets.
He renamed the remaining company Nebius and announced an ambitious goal to create a large AI infrastructure company.
After the split was completed, Nebius was removed from the sanction list and listed back on the Nasdaq.
2. Business Model
In the simplest of terms, Nebius is a data center business, similar to Amazon Web Services, Google Cloud, and Microsoft Azure. The company makes money by selling access to its data center infrastructure.
However, Nebius doesn’t handle general computing as their data centers specialize in AI workloads!
Nebius has tailored everything in its data centers to the very specific requirements that AI workloads have.
However, not all AI data center businesses are the same, as there are 3 key ways in which they earn revenue.
Colocation
Bare Metal
AI Cloud
Let’s expand on the differences.
2.1. AI Cloud vs Bare Metal vs Colocation
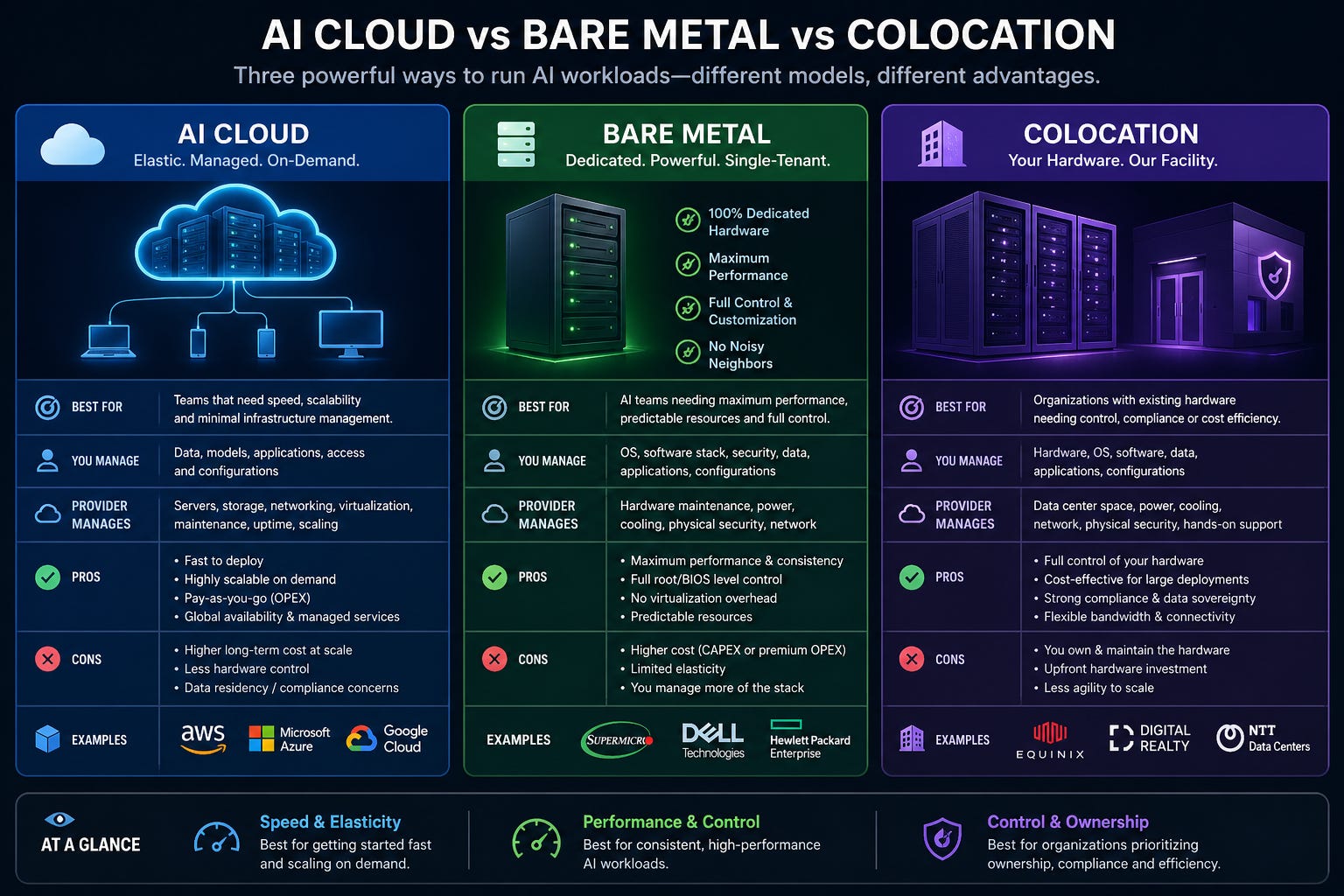
AI requires fundamentally different infrastructure than general-purpose cloud infrastructure.
Simply put, AI data centers use a higher number of powerful GPUs that eat a lot of electricity, requiring meaningful grid upgrades. Additionally, these GPUs generate more heat than a conventional data center, demanding improved cooling systems. This means that, unfortunately, using existing general-purpose data centers for AI workloads is just not economically viable.
This is why we are witnessing this extreme data center buildout boom!
In a colocation model, a company such as Cipher Digital builds the data center, secures energy, and equips it with cooling, networking, and other equipment. Then they secure a customer who signs a long-term lease agreement of 10+ years and brings their own GPUs to the facility. This model has the lowest value added and thus has the worst economics, generating the lowest price per MW.
Meanwhile, in a bare metal model, the owner of the data center is responsible for fully equipping the facility with all equipment, including GPUs. It then finds a customer who negotiates access to a pre-agreed number of GPUs for a set per-hour rental price. Bare metal customers use their own software to run AI workloads on these GPUs. As the data center operator provides the GPUs, the bare metal model has a higher value added than colocation, and thus has better economics, generating a higher price per MW.
However, the most profitable AI data center model is the AI cloud provider!
In this model, the data center operator provides advanced AI training and inference software. Purpose-built AI training clusters, model hosting, managed inference services, AI APIs, storage, networking, developer support, and more. An AI cloud doesn’t simply rent out space, like colocation, or rent out GPUs like in bare metal. An AI cloud is essentially an AI development, optimization, inference, and deployment partner for AI start-ups and large enterprises.
As revenues are software-driven, this model has the highest value added and thus generates the highest price per MW!
Each of the operating models has its own advantages and disadvantages.
In colocation, the data center operator is essentially a landlord, and such a model can be highly profitable if operated well. The key advantage is that it requires less capital to start, is easier to operate, and generates a more stable and predictable rental income from a small number of key tenants.
A bare metal is similar to colocation. But, if we use the analogy of a rental apartment, colocation is comparable to renting an apartment without any furniture, whilst bare metal is a fully furnished apartment. Meanwhile, an AI cloud could be comparable to a fully serviced apartment, with furniture, maids, a personal chef, nanny, tutor, and chauffeur.
An AI cloud might have the highest margins in theory, but it is also the most difficult model to operate. Companies must employ highly skilled software engineers to build the digital environment that AI start-ups need. This requires a lot of upfront capital and years of research and development. Furthermore, AI clouds must have big sales and customer management teams that manage a large number of small customers.
Most importantly, this area of the industry is highly competitive, filled with highly skilled start-ups, and it is led by Hyperscaler clouds with hundreds of billions of dollars at their disposal, such as Google, Amazon, and Microsoft.
Nebius has chosen a mixed business model, where it provides Bare Metal services to Hyperscalers Meta and Microsoft, while it provides AI Cloud services to others!
3. AI Cloud
I already touched on the difference between AI workloads and general cloud computing, but now let’s discuss it in more detail.
There are huge differences in each layer:
Infrastructure Layer
Platform Layer
Application Layer
Let me explain.
3.1. Infrastructure Layer
The infrastructure layer for AI is the actual physical equipment that does the work. In a normal cloud, you might not care much about what the physical server looks like, as long as it works. But in the world of AI, the physical design is everything.
The infrastructure layer includes
CPUs
GPUs
Server Design
Networking
Cooling
Because LLM’s and other AI models are so big, they require a level of power and speed that traditional data centers simply cannot provide.
The most important part of the infrastructure layer is the Graphics Processing Unit.
Originally, these chips were made for video games to help create pictures on a screen. However, scientists discovered that GPUs are much better at doing the specific kind of math needed for AI than the traditional CPUs found in most computers.
The core difference is that, while a CPU is like a very smart professor who can solve one hard problem at a time, a GPU is like a thousand students who can solve a thousand simple math problems all at once.
Since AI is mostly doing billions of math problems, the GPU has become the engine of the AI revolution. Nebius core business provides access to the most advanced GPUs made by Nvidia.

These chips are organized into different categories based on the blueprint of how the chip is built.
The most famous architectures currently used are called Hopper and Blackwell. The Hopper architecture includes the H100 and H200 chips, which have been the gold standard for AI training over the last few years. The Blackwell architecture is the newer, even more powerful version, including the B200 and B300 chips.

The table above shows that as you move to newer chips like the B300, the amount of memory and the speed of that memory increase dramatically. This is important because the intelligence of an AI model is stored in its memory.
If a model is too big to fit in the memory of the GPU, it will run very slowly or not work at all.
By offering many different types of GPUs, the platform allows users to choose the right balance between cost and performance. For example, the H100 is great for training, but the newer H200 or B200 models are better when the AI is actually being used by customers and needs to respond quickly.
A data center is basically a large building filled with rows and rows of computers. Most data centers are designed to be general-purpose, meaning they can run many different types of tasks.
However, Nebius builds AI-optimized data centers. Their first major facility is located in Mäntsälä, Finland. This location was built during Yandex’s time and was chosen for a few reasons, including the cold climate, which helps keep the computers cool without using too much electricity.

A core differentiator is that instead of buying standard servers from other companies, Nebius designs and assembles its own servers and racks.

This is a critical part of their full-stack approach. By designing the hardware themselves, they can make sure that every part of the server is optimized for the exact use case they are looking for.
An AI server is basically a Lego.
It contains GPUs, CPUs, memory, networking equipment, cooling systems, and more.

Nebius engineers decide how many Nvidia GPUs, AMD CPUs, Micron memory chips, and Broadcom networking chips each server needs, where they will be positioned, and how the liquid cooling system will reduce temperature.
The actual equipment assembly is done by outsourced electronics contractors such as Foxconn, Wistron, Inventec, or others.
Nebius engineers learn from each installation and modify designs to improve output and reduce costs!
This approach could potentially allow Nebius to have lower operating costs. The company claims that its servers use up to 20% less electricity than off-the-shelf servers.
Also, the liquid cooling system enables servers to operate at higher temperatures without damaging the system. Heat is a big issue for data centers, as hot servers are much slower than cold ones.
The performance of these custom-designed servers is so high that they have been used to build some of the most powerful computers in the world. The ISEG supercomputer, which is housed in the Finland data center, was ranked as the 13th most powerful supercomputer in the world and the 4th most powerful in Europe.

This shows that the platform is not just a place to rent some compute.
They make supercomputer-class infrastructure designed for the biggest AI projects on the planet.
When you are training a very large AI model, you cannot do it on just one.
You need thousands and even hundreds of thousands of GPUs all working on the same problem at the same time.
For this to work, the systems need to be able to talk to each other almost instantly. If the connection between the computers is slow, the GPUs will spend most of their time waiting for data to arrive, which wastes time and money.
This is why high-speed networking is a core part of the infrastructure layer.
Nebius platform uses Nvidia Quantum-2 InfiniBand.

This is much faster than the Ethernet cables used in most instances. In a Nebius GPU cluster, each server has a total network speed of 3.2 Terabits per second. This is made possible by giving each individual GPU its own 400 Gigabits per second connection.
This allows the GPUs to share information as if they were all part of the same giant chip.
Lastly, AI requires a massive amount of electricity and cooling!
According to some estimates, by 2028, data centers in the United States could use as much electricity as the entire country of Germany uses today.
This has made energy efficiency a very important topic for AI cloud providers. Nebius addresses this through a framework they call the Four Layers of Efficiency.

These layers are the model layer, the cluster layer, the fabric layer, and the data center layer.
At the data center layer, the focus is on a metric called Power Usage Effectiveness.
PUE measures how much energy is used for things like cooling and lights compared to the energy used by the core computing infrastructure. A perfect score is 1.0. While the global average for data centers is around 1.54, the Mäntsälä data center in Finland achieves a PUE of 1.13, demonstrating Nebius ability to design and operate energy-efficient data centers.
One of the most interesting parts of their energy strategy is heat recovery. When thousands of GPUs are working, they create a lot of heat.
Instead of just blowing this hot air into the sky, the Finland data center captures the heat and sends it into the local city’s heating pipes.
This hot water is then used to warm the homes of about 2,500 families in the city of Mäntsälä. Between 2022 and 2024, the facility provided over 50 GWh of heat to the community, which helped reduce the city’s carbon emissions and save costs.
This demonstrates Nebius’s ability to find clever solutions to difficult problems.
3.2. Platform Layer
While the infrastructure layer is the physical body of the cloud, the platform layer is the software that tells it how to behave.

For an AI developer, the platform layer is what they actually interact with to start their work. It handles the difficult task of organizing thousands of chips, making sure the right software is installed, and keeping everything running even if a piece of hardware breaks.
The platform layer includes:
Cluster Orchestration
Tools for Training AI
Optimizing GPU Performance
Systems for Managing Data
Orchestration is a fancy word for managing many computers as if they were one single system.
The most common tool for this is called Kubernetes.
However, standard Kubernetes can be very hard to set up for AI because it needs to know how to talk to GPUs and high-speed InfiniBand networks. Nebius provides a managed service for Kubernetes that does all this work automatically. When a user starts a Kubernetes cluster on Nebius, the system automatically installs the correct drivers and networking software.
This saves developers time that they would otherwise spend setting up the environment.
The platform also supports auto-healing, which is a very important feature for AI. If a training job is running for a long time and one GPU suddenly stops working, the auto-healing system will detect the problem and automatically restart the work on a new, healthy GPU. This ensures that the expensive training process is not wasted because of a small hardware glitch.
While Kubernetes is popular for many tasks, many AI developers prefer a different system called Slurm.
Slurm was originally built for supercomputers and is very good at scheduling large batch jobs where many computers must work together in a very specific way. To help these scientists, Nebius created a special tool called Soperator.
The Soperator is an open-source tool that allows Slurm to run inside a Kubernetes cluster. This gives users the best of both worlds, the modern flexibility of Kubernetes and the powerful scheduling of Slurm.
Users can use a configuration wizard to define how they want their cluster to look, including choosing which GPUs to use and how to prioritize different tasks. This allows for lots of control, where teams can fine-tune every part of their setup to get the most performance out of the hardware.
An advanced AI model is so big that it must be distributed across many machines.
This is like building a massive Lego set where a hundred people are all working on different parts of the same instruction book at the same time. For this to work, the people (or the computers) need to constantly talk to each other to make sure the pieces fit together.
The platform is designed to support the most popular distributed training frameworks, such as PyTorch and various Nvidia tools. Because Nebius is an official Nvidia Partner, they use a tested and optimized architecture that Nvidia has approved.
This means that the software and hardware are perfectly tuned to work together, which helps users get its absolute maximum speed, with no slowdowns caused by the cloud’s management software.
When a team of engineers is building an AI model, they don’t just do it once. They might try a hundred or a thousand different versions, changing small things each time to see what works best. Keeping track of all these versions, the data used, and the results can be a nightmare.
This is what model management is for.

Nebius provides a Managed Service for MLflow to solve this problem.
MLflow is an open-source platform that helps teams track their experiments and manage the lifecycle of their models. It allows developers to see all their training results in one single interface, compare different versions of a model, and choose the best one to use in a real product.
By providing this as a managed service, the platform takes care of all the technical setup, so the engineers can focus on the science of AI instead of the logistics of managing files.
Next, GPU computers are very expensive to run. For many companies, they don’t need the same number of GPUs all the time. They might need 1,000 GPUs during the day to run experiments, but only 10 at night to handle simple tasks.
Auto-scaling is a feature that automatically adds more computing power when there is a lot of work to do and removes it when it is not needed.
The platform’s autoscaler is integrated directly with the Kubernetes service. It makes decisions based on whether there are tasks waiting in line.
When the line gets too long, the system automatically creates more GPU nodes. To save even more money, the platform suggests using a small group of cheap CPU computers to run background tasks like networking and monitoring. This allows the expensive GPU nodes to be turned off completely when they aren’t doing actual AI work, which can significantly reduce the total cost of the project.
Most importantly, an AI model is only as good as the data used to train it.
Before the training starts, a huge amount of raw data must be collected, cleaned, and organized. This is called data preparation, and it often requires its own complex computer system.
Nebius provides a managed service for Apache Spark to help with this.

Spark is a tool that can process massive datasets by splitting the work across many machines.
In the Nebius ecosystem, developers can build an entire data pipeline, which is like an assembly line for data, all on the same platform. This includes fast storage for training, object storage for holding billions of files, and specialized databases for searching through data.
They also offer a Data Transfer Service that makes it easy to move large amounts of information from other cloud providers, like AWS into the Nebius cloud.
This is critical because moving petabytes of data can often be the slowest part of starting a new AI project.
Do you like this report?
Become a Paid Premium member to see dozens of exclusive pay-walled equity research reports such as this.
Curious about which stock I own?
Full portfolio with all holdings, cost basis, and unrealised gains is visible to Premium members. I do weekly updates and detailed monthly reviews. Premium members are also notified of all sales and purchases using the pay-walled Substack Chat.
The annual plan is available for 50% cheaper per month than the monthly plan.
3.3. Application Layer
The application layer is the final piece of the puzzle.
This is where the work of the engineers and the power of the hardware finally turn into something useful for end users. The focus of the application layer at Nebius is to make everything as simple and automated as possible.
The Application Layer consists of:
Model Training
Inference
Model Deployment
Developer Tools

Training is the most well-known part of the AI process. It is when a model learns by looking at millions of examples. On the Nebius platform, training is supported by a team of experts who help customers. Because training is so expensive and difficult, having experts who can help with the setup is a major benefit.
One unique part of the training offering is that the platform’s own internal AI researchers use the same tools as the customers.
They call this dogfooding the platform. When the internal team trains their own models, they find and fix problems before a customer ever sees them. This ensures that the platform is actually built for the way real AI practitioners work.
For example, Nebius provided Higgsfield with its fully managed AI cloud platform, enabling them to launch model training in under one hour and run stable, large-scale jobs. Their infrastructure handled scheduling, scaling, and networking, allowing Higgsfield to support 5M video generations per day and reach 22M+ users without performance issues.
As a result, Higgsfield dramatically accelerated iteration and growth, reaching a $200M run rate in just 9 months.
However, after a model is trained, it needs to be put to work. This is called inference.

If you ask a chatbot a question, the time it takes to get an answer is the inference time. For a business, inference is often the most important part because it is what their customers actually see.
The Nebius platform has a strong focus on making inference super-efficient and economically viable.
Simply put, Nebius wants it to be fast and cheap. They use specialized software like vLLM to optimize how the models run on the GPUs. This has allowed companies like Brave Search to provide real-time AI summaries for millions of users every day with very low delay.
By optimizing the entire stack, the chips and the software, Nebius aims to deliver inference speeds that are much faster and cheaper than competitors.
Previously, to run an AI model, you had to rent a whole server and manage it yourself. This is a lot of work. To fix this, Nebius introduced Serverless AI services.

Serverless means the developer doesn’t have to worry about the computers, as they just provide their code or their model, and Nebius handles everything else. There are three main serverless services:
DevPods
Jobs
Endpoints
DevPods are like a developer playground. They provide a ready-to-use environment where a programmer can start writing code immediately without setting up any drivers or software.
Jobs are for running a single task, like training a model for a few hours. Once the task is done, the computer is automatically turned off, so the user doesn’t have to pay for it anymore.
Endpoints are for serving models. They provide a web address where an app can send a question and get an answer from the AI model in seconds.
Next, to make the cloud easy to use, the platform provides several different interfaces.
The most basic way is through a web console, which is like a website where you can click buttons to start servers.
However, for large projects, developers prefer to use a command-line interface. This is a tool where you can type commands to manage your cloud resources.

For even more advanced users, the platform supports Infrastructure as Code using a tool called Terraform.
This allows a team to write a document that describes their entire AI system, how many GPUs, how much storage, and what network settings they need. They can then run this document, and the cloud will build the entire system automatically in minutes. They also offer software development kits for languages like Go, which allow developers to build the cloud features directly into their own software.
But one of the most powerful parts of the application layer is the Nebius Token Factory.
This is a managed inference service.
Instead of renting a GPU, you simply pay for every token that the model generates. An AI token is a small unit of text (like part of a word) that a model processes as a single piece of input or output during computation.
This is a very popular way for startups to use AI because they don’t have to worry about managing any hardware at all.
The Token Factory gives users access to over 60 different models, including famous ones like Llama, Mistral, OpenAI, and DeepSeek.
It also includes auto-scaling, so if a million people suddenly start using your app, the Token Factory will automatically add more power to handle the traffic without you having to do anything.
Another crucial piece of Nebius offering is Tavily, which was acquired recently for $275M.

This is a big step toward Agentic AI. To understand why this is important, you have to understand the difference between a chatbot and an AI agent.
A chatbot just talks to you based on what you ask and what it already knows.
An AI agent is a digital assistant that can actually go out and do things for you, like researching a topic on the web, finding relevant information in your ERP, or booking an invoice in the accounting system.
The problem with most AI is that it only knows what was in its training data. If you ask it about a news story from today, it won’t know the answer. Tavily solves this by providing agentic search.
This is a search engine built specifically for AI agents.
When an AI agent needs more information, it uses Tavily to search the internet and get back a response in a format that’s purposefully designed for AI agents to understand.
By combining the reasoning power of the Token Factory with the real-time search power of Tavily, the platform allows developers to build agents that are grounded in facts and never have out-of-date information.
This is critical for use cases where having the 100% correct information is crucial for a successful outcome.
4. Data Centers
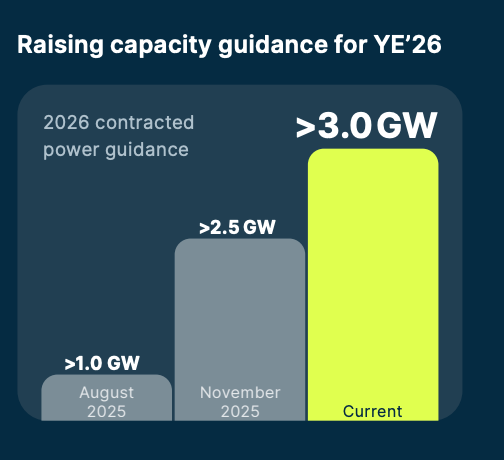
Per Nebius Q4 2025 earnings report, the company plans to have 16 data centers with contracted 3GW of energy capacity by the end of 2026.
Let’s look at the largest and most important of these projects.
4.1. Finland
Finland has become a core geography for Nebius.
The country offers a cool climate, which is a major advantage for data centers because it reduces the amount of energy needed to keep the computers from overheating. Additionally, Finland has a stable power grid and access to renewable and relatively affordable energy for European standards.
The Mäntsälä facility is a facility fully owned by Nebius.

As I mentioned in the infrastructure layer section, this data center uses an innovative heat recovery system that captures the excess heat produced by the servers and pumps it into the local municipal heating network.
In early 2026, Nebius expanded this site to 75 MW.
In March 2026, Nebius announced plans for a much larger project, a 310 MW AI factory in the city of Lappeenranta.
This facility will be one of the largest dedicated AI compute deployments in Europe. Construction began in the Pajarila district, with the first capacity expected to be available to customers in 2027.
This new site will use the latest technology from Nvidia, specifically the Blackwell and Vera Rubin chip platforms.
The project is estimated to require a $10B investment and is being developed together with the Finnish company Polarnode, so this will be a colocation facility.
4.2. Kansas City
Nebius’s largest project to date is located in the Kansas City metropolitan area.
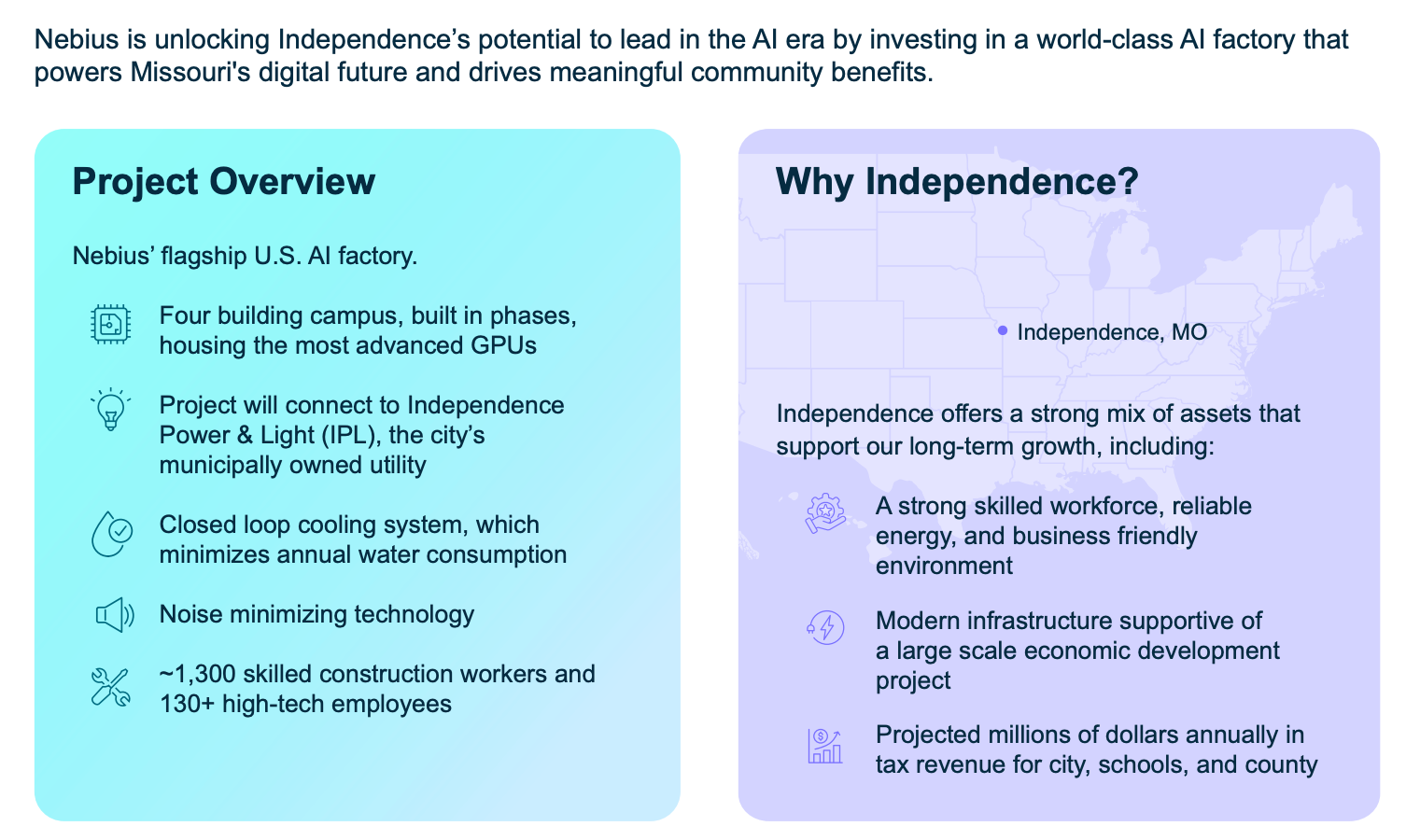
This project is a massive AI factory campus designed to reach a total capacity of up to 1.2GW.
Construction is expected to begin in early 2026 and will happen in stages over a period of 3 to 5 years.
One of the most important parts of the deal is that Nebius pays the full cost of its electricity and any infrastructure upgrades. This ensures that the electricity rates for local residents do not go up because of the data center.
Data centers usually use a lot of water for cooling, which can be a concern for local residents. Nebius is using a closed-loop cooling system in Independence. This system requires a one-time fill of about 1M gallons per 200 MW building, but after that, it only needs about 20% replenishment each year.
This is a very small amount of water compared to traditional data centers and is roughly equal to what a typical restaurant uses in a year.
This project is entirely owned and operated by Nebius, without colocation partners.
4.3. New Jersey
The data center in Vineland, New Jersey, is a critical part of Nebius’s growth as the site is closely tied to a massive $17.4 billion, 5-year contract with Microsoft.

The Vineland campus is planned to span 2.6M square feet across 6 buildings and will have a power capacity of up to 350 MW.
A unique feature of this site is that it generates 85% of its own electricity on-site using natural gas generators.
It allows Nebius to operate without putting too much stress on the local power grid, which is often a problem in New Jersey. The project has been moving very quickly.
The first phase, which included a 150,000-square-foot facility, was delivered in just 20 weeks and is already operational as of early 2026.
However, the speed of construction has caused some concerns among local residents. Some community members have raised questions about noise, air pollution from the gas generators, and the impact on the local underground water supply.
This site is being developed in partnership with a colocation provider, Data One.
4.4. Alabama
Nebius is also expanding into the Southern United States with a data center project in Birmingham, Alabama, with a 300 MW capacity.

The Birmingham site is a brownfield asset, which means it was previously used for industrial purposes. Developing a brownfield site is faster than starting from scratch (a greenfield site) because the infrastructure and utility connections are already there.
The site is fully owned by Nebius.
This could be an interesting template for the future. There are a lot of industrial sites not only in the US, but in Europe and South America that have closed down for various reasons. These areas already have the grid connections, and eager politicians want to put something in an empty factory.
There are drawbacks, as brownfield data centers are generally smaller and need to be designed to get the most out of the location’s limitations, instead of customizing everything to get the best performance, as in greenfield developments.
But what they lose in size and customization options, they win in speed and cost.
4.5. Colocation
Nebius uses a hybrid approach to build its network.
While they are building massive campuses that they own (like in Missouri and Finland), they also use colocation.
As I explained in the business model section, colocation is when a company rents space, power, and cooling in a data center owned by someone else. This is a very common practice in the data center industry.
Colocation sites reduce deployment timelines and mitigate permitting risk, particularly in regions where grid access or regulatory approval is a constraint.
This strategy is much different from Iren!
Iren builds and owns large-scale data centers, giving it tighter control over energy sourcing, design efficiency, and long-term operating costs. Instead of having many smaller locations such as Nebius, Iren has fewer but larger ones. For instance, their Sweetwater campus in Texas will have 2GW of capacity when completed.
The trade-off is that Nebius gains speed and lower upfront investment but has less control over infrastructure and direct costs.
While Iren gains efficiency and control but faces slower deployment and higher capital requirements.
Both models can work. Iren is a bare metal compute provider to the largest companies in the world. Meanwhile, Nebius is competing with Hyperscalers for AI start-ups, offering them a whole suite of AI services as explained in the platform and application layer sections.
Ideally, Nebius hopes that the higher margin in cloud services compared to bare metal rental compensates for the higher operating costs. Whether this strategy will work is yet to be seen.
5. Customer Deals
As of today, Nebius has signed two large bare metal deals with Hyperscalers:
Microsoft
Meta
Let me explain these deals.
5.1. Microsoft
Last year, Nebius signed a $17.4B-19.4B 5-year deal with Microsoft, which instantly sent its stock price up almost 50% in a single day!
As I mentioned in the data center section, in partnership with a colocation company, Data One Nebius is building a new data center in New Jersey, with an initial planned gross capacity of 300MW, with the potential to expand it to 400MW total energy capacity. Microsoft will rent access to 100K Nvidia GPUs, which could demand 180-220MW, but we need to add 20% extra for additional IT equipment, resulting in 216-264MW.
This means that Microsoft could take up around 72-88% of the initial capacity and 54-66% of potential capacity!
At $17.4B for 5 years, that amounts to $3.48B per year, for 100K GPUs.
Revenues of $34.8K per GPU and $3.97 per hour!
This is a very strong anchor tenant that will enable Nebius to basically cover all costs and have a decent margin. The remaining capacity will be used for Nebius’ cloud business, where Nebius will earn better margins.
The deal will enable Nebius to cheaply borrow money through a vehicle known as revenue-backed loans.
Essentially, because Microsoft is such a large, profitable, and stable enterprise with a credit rating literally better than the US government, banks and investors are willing to lend money to Nebius at highly attractive terms, because the probability that Microsoft will not honor its contractual obligations is extremely low.
Thus, Nebius will borrow money using the Microsoft deal as collateral!
There are many ways this could be structured. One way would be for Nebius to sell these receivables at a discount of, let’s say, 3-7% to a special vehicle that is funded by a consortium of lenders, and Microsoft would transfer payments directly to that special vehicle.
Additionally, while it was not confirmed in the press release, later financial statements show that Microsoft prepaid about $1.6B.
But let’s expand on that in a bit.
5.2. Meta
While the deal with Meta was likely in the works for months, as such agreements are difficult to negotiate, Nvidia’s $2B investment, strategic partnership, and Rubin allocations were likely crucial factors that convinced Zuckerberg that Nebius is the real deal.

This deal agreement is structured in 2 tranches:
$12B of dedicated capacity
$15B of optional capacity
The foundational element of the deal is a $12B commitment for dedicated AI compute capacity.
Under this supply agreement, Nebius will provide Meta with massive, localized GPU clusters for Meta’s exclusive use.
Typically, Cloud customers share GPUs with other Nebius customers. Meta won’t be sharing any GPUs with other customers and will be physically separated from GPUs used by other Nebius customers.
Dedicated GPUs provide Meta with consistency, full performance, low latency, and stronger security, since no other users are competing for GPU compute. Shared GPUs are cheaper but can suffer from variable performance, making them less reliable for demanding or workloads.
Delivery of this capacity is scheduled to begin in early 2027, marking one of the first and largest commercial deployments of Nvidia’s Vera Rubin architecture.
This dedicated tranche ensures that Meta’s internal research teams, particularly those working on the Llama 4 and Avocado foundational models, have guaranteed access to the best AI chips in the world.
The remaining $15B of the contract value is structured as a commitment for Meta to purchase additional available compute capacity across upcoming Nebius clusters.
This tranche contains a clever monetization mechanism as Nebius intends to market this capacity to third-party enterprise and startup customers first, where it can get higher retail margins.
Meta serves as the guaranteed backstop, committing to purchase any remaining capacity that is not absorbed by the broader market. For Nebius, this provides a revenue floor of up to $27B, significantly de-risking its aggressive $20B capex roadmap for 2026.
Essentially, Nebius has secured the right to shop around to see if they can get a higher price or better payment terms. If they can’t find someone willing to pay more than Meta, the capacity will go to Meta.
This is clearly a sign that Meta has such strong demand for compute that Nebius had the upper hand to get this carveout.
Nebius doesn’t want to give up all its capacity to one client, as they are also focused on building their AI Cloud that competes with AWS, Oracle, Azure, and Google Cloud.
5.3. Profitability?
Unfortunately for us analysts, Nebius is not very forthcoming with contractual details. We don’t know how many MW this contract is for, how many chips are to be used, the price per hour, the price per MW, or whether Meta will pre-pay or not.
Such secrecy is understandable, as the industry is very competitive and there are many parties involved!
Nebius doesn’t want to publicize the price per hour that it charges Meta, as its wholesale price is likely significantly lower than the retail price. Revealing it could put downward pressure on retail prices.
At the same time, Meta doesn’t want others to know how much they are pre-paying, so that other cloud deals that they sign don’t ask for the same.
Also, Nvidia doesn’t want other customers to know on what contractual terms they are selling Rubin chips, because they could demand similar terms. We don’t know about bulk discounts or whether Nvidia is providing any vendor financing or generous payment terms.
My guess is that all these terms are very generous to Nebius, as Nvidia wants them to succeed to become large purchaser of Nvidia chips.
Nebius is still early in its journey and is capital-constrained, by providing generous payment terms, it would greatly help them. But that’s all it is, a guess. But we can go to Nebius financial filings and management statements to find some clues.
“How are we going to finance the CapEx?
So obviously, we will first finance it from our cash flows…
But most importantly…..we will continue to receive cash in 2026 from the favorable terms of our long-term contracts.
This cash flow will actually finance the majority, actually around 60%, maybe even more, of all of our CapEx needs in 2026.
So how are we going to finance the remaining amount?
As of today, we don’t have any corporate level debt.
We don’t have any asset-backed financing,
We don’t have any bank revolver,” Ofir Naveh, Chief Operating Officer of Nebius, Q4 2025 Earnings Call.
So, as Ofir says, 60%+ of capex will come from the favorable terms of our long-term contracts and the rest from contracted cashflows and conventional financing.
In Q4 2025, Nebius collected $1.6B from deferred revenue.

This is revenue that customers have already paid for, but Nebius has yet to deliver the service to recognize revenue. Simply put, these are customer pre-payments. The balance sheet further categorizes it with $1.3B is listed as non-current and $0.3B as current. This means that from the $1.6B that Nebius collected, it plans to recognize $0.3B as revenues in the next 12 months.
So the vast majority of this pre-payment was for services that will be recognized in 2027!
This demonstrated that the demand is so strong that Nebius is able to receive significant payments from customers more than a year before delivering services to them.
We also see a large spike in accounts payable, going from $228M to $1.2B. Many analysts have interpreted that favorable terms of our long-term contracts quote as pre-payments, but it also clearly means vendor financing and attractive payment terms.
If Nebius can receive early payments from customers while simultaneously delaying payments to suppliers, it can drastically reduce immediate cash requirements!
Nebius is essentially getting interest-free loans from both its supplier and the customer. It helps smooth out cash outflows, reduces interest costs, helping Nebius to scale quickly.
As we don’t have any concrete figures, I will have to speculate using back-of-the-napkin math and my own estimates to calculate how profitable this agreement could be.
Modeling about $10.7B in capex requirements.
Assuming 70% EBITDA margin, the $12B part could generate about $1.68B in EBITDA per year.
1 year service $2.4B pre-payment from Meta, credited towards years 3-5.
24-month vendor financing of 10% of capex, around $1.6B.
Conventional bank loans of $5.3B, about 50% of capex, at 7% interest rate.
Loans refinanced at the end.
Terminal value of $6.5B.

I get levered IRR of about 32%.
That seems decent to me. But granted, this model is very sensitive to terminal value, pre-payment size, vendor financing, and loan amount.
Lastly, we don’t know if the Meta agreement is pure bare metal GPU rental or if Nebius is also providing some kind of cloud software. If they do, that could drastically improve margins.
Meta is not Microsoft, they don’t have as much experience in running cloud software and are more likely to use various software solutions that Nebius offers.
6. Subsidiaries
When Nebius separated from Yandex, they kept not only the core AI data center cloud business but also various interesting non-core assets.
Avride
TripleTen
Toloka
ClickHouse
6.1. Avride
Nebius’ autonomous driving subsidiary Avride alone could be worth $4-6B!

It is quickly scaling and cornering a niche in small robot delivery.
Through their partnership with Grubhub, these food delivery robots are delivering around 1,200-1,400 deliveries a day at the Ohio State University campus. While this was already known, recently the company revealed that they have completed over 100,000 deliveries on said campus. The deliveries are made in around 15 min, drastically improving convenience and user experience.
Last year, it was announced that after the smashing success of this pilot, Grubhub is bringing this partnership to the University of Arizona!
If they can deliver 100,000 meals on a single campus, there is a potential for millions of deliveries if this technology is brought to thousands of large universities in the US and Canada.
This might seem trivial, but I think the university food delivery robot business alone could be a multi-billion-dollar vertical, and this success demonstrates their ability to expand!
Furthermore, Uber Eats is deploying Avride’s small autonomous delivery robots for food delivery in Dallas and Jersey City, in addition to Austin. This is going well, and companies are planning to enable grocery delivery as well.
Grocery delivery in urban areas using small robots is another potential multi-billion-dollar vertical!
Avride and Nebius have a very close relationship. Training a self-driving car requires a massive amount of computer power, and Avride runs its AI models on the Nebius AI cloud.
This represents Nebius’s exposure to physical AI, where software intelligence is paired with real-world deployment.
Both delivery robots and robotaxis are built on a shared architecture that includes perception, sensor fusion, mapping, and motion planning. This improves capital efficiency by spreading R&D costs across multiple verticals.
The partnership and investment from Uber is a strategic inflection point for Avride. In late 2025, Avride secured up to $375M in investments and commitments from Uber and Nebius.
This builds on a commercial partnership where Avride’s delivery robots are already integrated into Uber Eats in Jersey City, Austin, and Dallas. Robotaxis were launched on the Uber platform in Dallas in December of 2025, and by some reports, there are about 200 vehicles on the roads.

This relationship provides Avride with access to consistent demand, real-world operating data, and a trusted consumer interface without requiring Avride to build its own network.
6.2. TripleTen
One of the biggest problems in the AI industry is that there are not enough people who know how to use it.
TripleTen is an edtech company that helps people learn new tech skills. Nebius reported this segment’s revenue was up 88% in 2025.
TripleTen offers programs in areas like AI software engineering, data analytics, and cybersecurity. The platform’s curriculum has been updated around AI-native workflows, including an AI Automation track launched in 2025.
The strategic fit inside Nebius is clear, companies can lease AI infrastructure faster than they can retrain their staff. TripleTen addresses this bottleneck.
6.3. Toloka
AI models are not perfect, and they need humans to check their work and give them feedback.

This is what Toloka does. It’s a data annotation and labeling platform that provides a judgment layer for the AI world.
Toloka has shifted from mass-market crowdsourcing toward an expert network of more than 10,000 verified specialists across 20 domains and 40 languages.
In February 2026, Nebius and Toloka announced plans to integrate Tendem into the Nebius ecosystem.
Tendem is a hybrid human-AI system that allows AI agents to escalate uncertain edge cases to human experts. This hybrid workflow is 53% faster than a human-only baseline, with task quality improving by 21.3%.
This is particularly important for regulated enterprises, such as those in finance or healthcare, where AI decisions must be verified and audited. Toloka helps determine whether the cargo of the AI models is safe enough to ship.
6.4. ClickHouse
ClickHouse builds a high-performance analytical database designed for extremely fast queries on massive datasets.

This service is becoming extremely important in the age of AI, as having well-organized and labeled databases that are easily accessible is a must for LLM models to give fast responses to prompts. Their databases have trillions of rows.
This has made ClickHouse an important vendor for the $800B AI start-up Anthropic!
ClickHouse provides:
Promt Analytics
AI Token Usage Monitoring
Fine-tuning Dataset Exploration
Real-time Model Analytics
Recently, it was reported by media outlets that ClickHouse has hired a series of employees, which would hint at them preparing for an IPO.
The company recently raised $400M funding at a $15B valuation, but considering the strong demand for their services from some of the hottest AI start-ups such as OpenAI, Anthropic, and Mistral AI, I find it likely that the IPO would set them up for a $20-30B market cap.
This could mean that Nebius stake of around 28% could be worth around $5-8B!
7. Competitors
The demand for AI services is booming, so hundreds of billions of dollars of capital have entered the industry. Today, the industry might be supply-constrained, but that doesn’t mean that there is no competition.
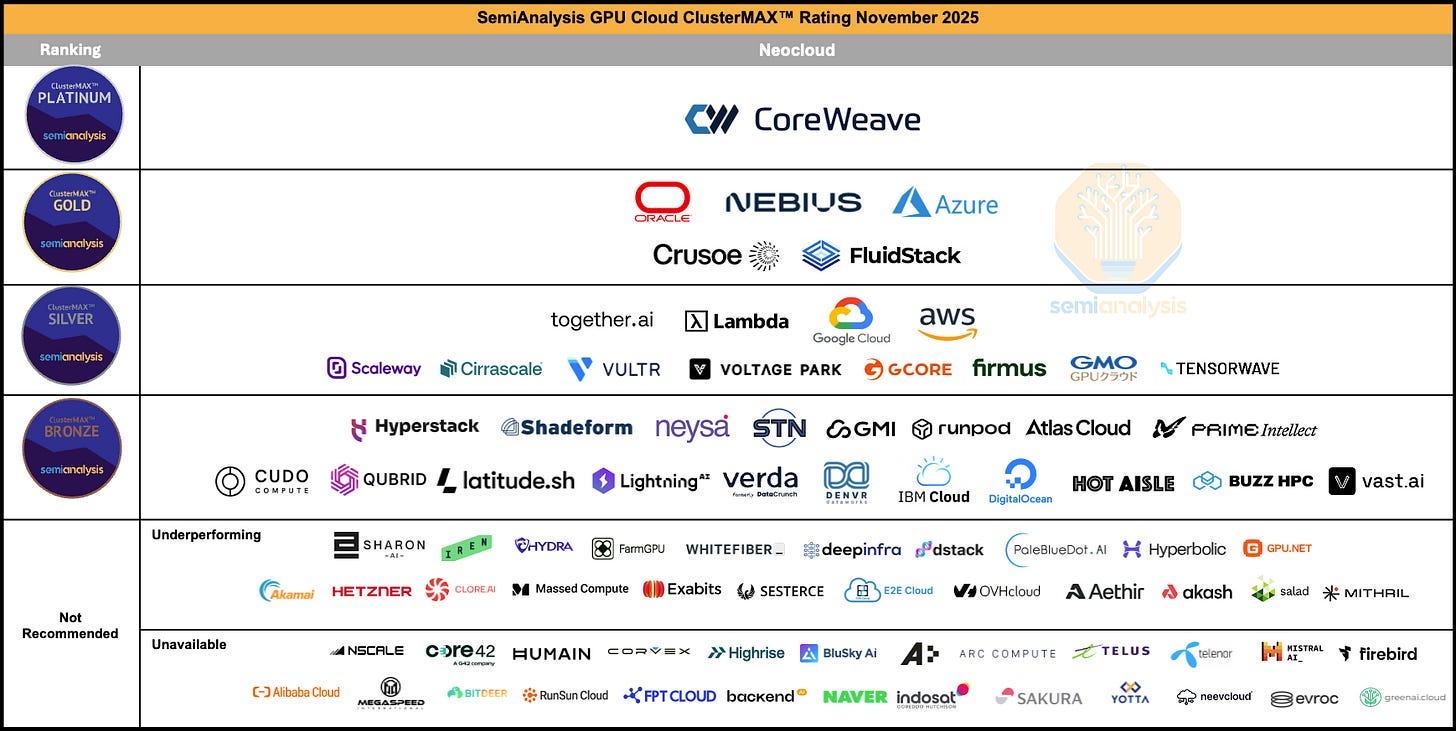
In fact, the AI computing industry is starting to get very crowded, with 2 key types of players:
Hyperscalers
Neo-Clouds
7.1. Hyperscalers

The Hyperscalers are the biggest names in tech, such as Amazon, Google, Microsoft, and Oracle.
They have more money, more customers, and more data centers than anyone else.
The size of these companies is hard to imagine. While Nebius is proud to have a few data centers, Google has more than 40 large data center regions all over the planet. This scale gives them a huge advantage because they can serve customers in almost every country with very low delays.
Another big advantage is customer entrenchment.
Most big companies already use Microsoft or Amazon cloud hosting and other software services. So it is very easy for them to just click a button and start using that same company’s AI tools.
Hyperscalers create a walled garden.
They make it very easy to stay inside their system but very hard to leave.
For example, if a company has all its data stored on AWS, it might be very expensive or slow to move that data over to Nebius to train an AI model. This keeps customers stuck with the giants, even if a smaller company like Nebius offers a better service.
The way these companies get money is also very different.
Hyperscalers are so profitable that they can pay for new AI chips using the cash they have in the bank! They don’t have to issue equity, convertible notes, or expensive debt.
They have the highest access to capital and some of the lowest cost of capital.
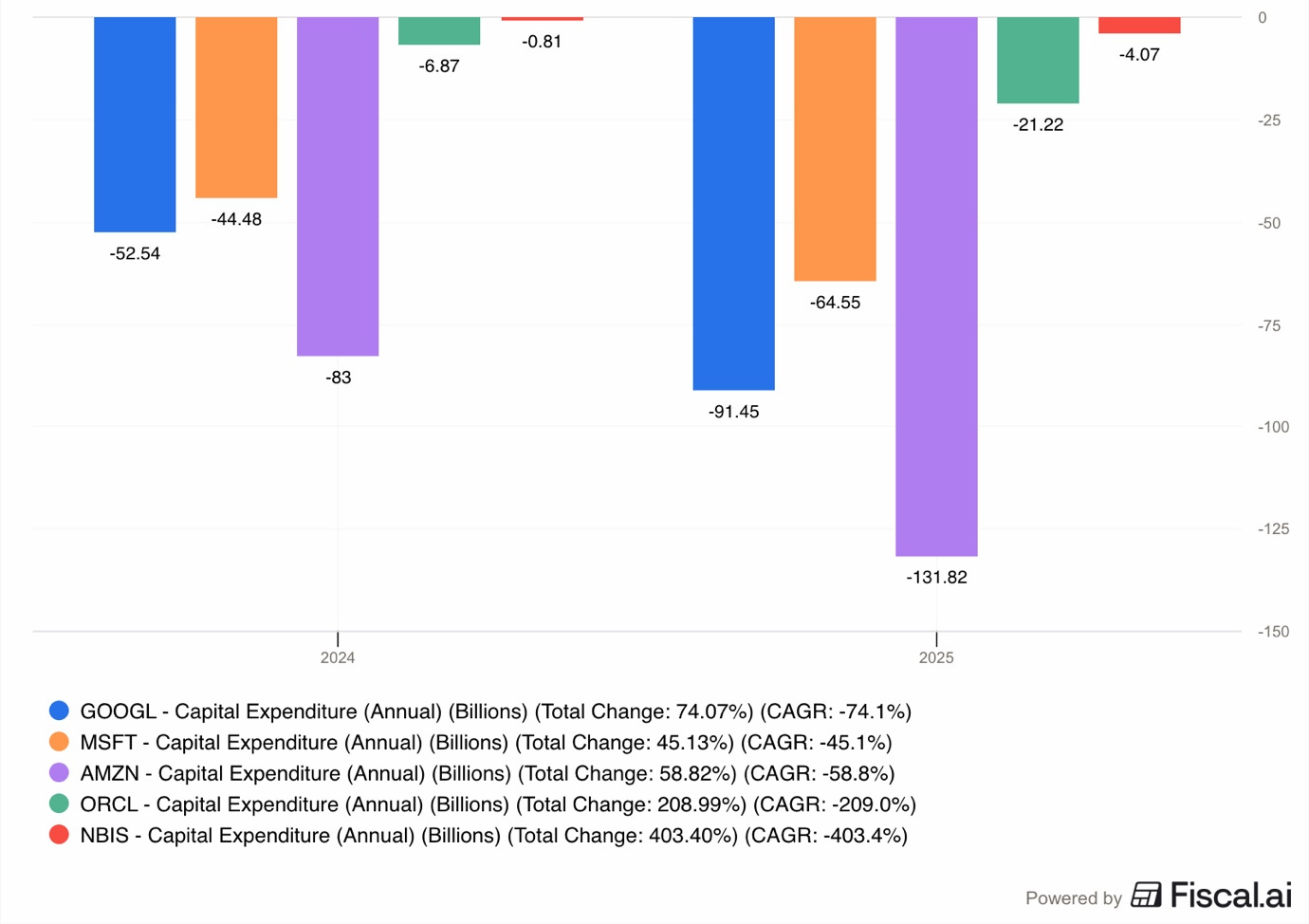
As you can see in the graph above, in 2025, Google spent $91.5B on capex, Microsoft $64.6B, and Amazon $131.8B compared to $4B of Nebius!
Because they buy so much equipment, they can get better terms from suppliers such as Nvidia, Micron, AMD, Intel, or others.
Nebius, on the other hand, is still growing, unprofitable, and while it has some cash, it has to be much more careful. To build the massive data centers it wants, Nebius will need to borrow a lot of money or sell more of its own stock.
If the stock market goes down or if interest rates go up, it becomes much harder for a company like Nebius to get the money it needs to keep building.
7.2. Neo-Clouds
Neo Clouds are the newer, smaller companies that are competing directly with Nebius. The most famous ones are CoreWeave and Iren.
These companies can be faster than the giants because they do not have to worry about legacy tech debt, as they only focus on the newest AI chips.
Sometimes it is easier to just build everything from scratch instead of upgrading existing infrastructure.
A meaningful competitor is Iren, which has a very different background from Nebius.
Iren started as a Bitcoin mining company. Because Bitcoin mining requires a lot of electricity and big data centers, the company already knew how to build the physical parts of a data center.
They are considered an asset-heavy company because they own their own buildings and land. Iren’s main goal is to get the cheapest electricity possible, sometimes as low as $0.03 per kilowatt-hour, by building in remote areas.
Nebius is different from Iren because Nebius focuses much more on software. While Iren just provides bare metal. Nebius provides a whole platform that helps developers manage their AI work.
CoreWeave is another major competitor.
CoreWeave has grown extremely fast by taking on huge amounts of debt to buy Nvidia chips. As of 2025, CoreWeave had over $46B in liabilities on its balance, which is an absolutely mind-boggling amount for such a young company.
Essentially, Nebius competes with Neo Clouds for bare metal contracts with Hyperscalers, and it competes with Hyperscalers for AI start-ups.
So, in the future, it could be that Hyperscalers prefer to give their bare metal business to a sole focus Neo Clouds like Iren and CoreWeave, who don’t compete with Hyperscalers for the AI cloud business.
8. Risks
8.1. Dependency on Nvidia
A huge risk for Nebius is that its entire business depends on one company, Nvidia.
Nvidia makes the H100, H200, Blackwell, and soon, Rubin chips that are the engines of the AI world.
Without these chips, Nebius would have nothing to sell.
At the same time, if Nvidia experiences any production, supply chain, quality, or technology issues, Nebius could be severely affected. If Nvidia can’t deliver on its performance promises, then Nebius customers won’t want to use them or will demand significant discounts.
To strengthen their relationship with Nebius, in March 2026, Nvidia made a very big move by investing $2B into Nebius.
This made Nvidia a part-owner of Nebius, with about an 8.3% stake in the company.
On one hand, this is good because it means Nvidia wants Nebius to succeed and will likely give them chips first and on good terms.
On the other hand, it means Nebius is now more tied to Nvidia’s technology.
If Nvidia has any problems, or if a different company like AMD starts making better chips, Nebius might be stuck with old technology for which there is less demand.
Moreover, if the big hyperscalers like Amazon start making their own chips instead of buying them from Nvidia, Nebius could lose its biggest potential customers.
8.2. Construction Delays
Building a data center is not like building an office, as they are infinitely more complicated.
As these buildings are so large and use so much energy, many people do not want them in their neighborhoods.
For instance, in Vineland, New Jersey, residents have started protesting against the data center.
First, they complain about a loud metallic humming noise that comes from the cooling fans, which makes it hard for people to sleep.
Second, they are worried about water. Data centers use millions of gallons of water every year to keep the computers from melting. In places like Vineland that have had droughts, people are afraid there won’t be enough water left for farming or daily needs.
Even if the residents are assured by Nebius that these issues are only temporary and that mitigating steps are being taken, getting enough electricity is another huge problem.
In some instances, it can take more than a year just to get the right permits to connect a data center to the power grid.
In countries with terrible business regulations, such as France and Germany, these issues could take even longer. There are reports that some prospective data center entrepreneurs are being told that they would have to wait even 10 years to connect their data center to the grid in Germany. No wonder the German economy has been performing so poorly for a decade.
In some areas, the electricity utilities are so overwhelmed that they are asking the government to let them skip some rules so they can build faster.
This could lead to potential safety problems in the future.
There are also supply chain issues. For example, some electrical parts like transformers and switchgear can take 40 to 60 weeks to be delivered.
If a data center is finished but doesn’t have these parts, it cannot turn on, and Nebius not only incurs costs every day it stays dark, but it also doesn’t make revenues.
Continuous expenses and no revenues could be a recipe for a financial disaster.
8.3. Industry Overcapacity
There is a danger that the world is building too many data centers too fast.
If there is more supply of GPUs than demand, the price that Nebius can charge will go down.
For example, the State of Kubernetes Optimization Report by Cast AI in April 2026 found that in many companies, up to 95% of the AI chips they own are actually sitting idle.
This report is just from a single company focusing on one area of the industry, and excludes the hyperscaler clouds. However, the potential downside trend is clear.
Companies have been buying chips because they are afraid of running out. If these companies realize they have too much computer power, they will stop renting from Nebius.
When that happens, all the cloud companies might start a price war, and keep lowering their prices to steal each other’s customers.
If the prices drop too low, Nebius might not be able to pay back the billions of dollars it spent to build the data centers in the first place.
8.4. AI Cloud Failure
Nebius is trying to build a complex software platform at the same time it is building giant data centers.
This is very difficult.
Most of the hyperscalers have been building cloud software for 20 years. Nebius is still very new and is building its offering as it goes.
If a big company like Higgsfield AI wants to train a new AI model, they need to know that the software will work perfectly and never crash.
If Nebius’s software has bugs or is hard to use, customers will go back to the established giants even if Nebius is cheaper.
Nebius has many great engineers, but they are competing against thousands of the highest-paid engineers in the world, making millions of dollars at Google and Amazon. They simply have much more experience in the global cloud market.
8.5. Bursting of the AI Bubble
Many experts are worried that the current hype around AI is a bubble, like the Dot-com bubble of the 2000s. In a bubble, people invest huge amounts of money based on hopium rather than real profit.
In 2026, many investors are starting to ask for proof that AI is actually making businesses real money.
If big companies spend billions on AI but don’t see their profits go up, they might stop spending. Some people worry that if the FED raises interest rates to fight inflation, the funding that is fueling the AI boom could become more scarce.
If the bubble bursts, the value of Nebius’s stock will crash, and it might not be able to finish the massive projects it has started.
In such a scenario, bankruptcy or a 90%+ crash in the share price is a realistic outcome.
9. Opportunities
Even with all these risks, there are huge opportunities for Nebius.
Because the AI world is changing so fast, being a small and focused company can actually be an advantage.
9.1. Hyperscaler Bare Metal
One of the most interesting opportunities for Nebius is that the big Hyperscalers are so capacity-constrained that they are actually becoming its customers.
Sometimes, a company like Microsoft or Meta has so much demand for AI that it cannot build its own data centers fast enough. Instead of telling their customers no, they rent extra capacity from companies like Nebius.
In this setup, the advantage is that Nebius doesn’t have to worry about finding small customers.
As I already explained in the customer deals section, Nebius has a $17.4B contract with Microsoft and a $12 and $15B with Meta.
This gives Nebius some guaranteed income, which makes it much easier for them to get loans from banks to build more data centers. Then the company can reinvest earnings from these deals into building its own AI cloud offering.

Per Bloomberg estimates, Microsoft, Meta, Amazon, and Google will spend over $600B in capex in 2026 alone.
There is a significant opportunity for Nebius to capture this growing demand.
9.2. Inference
For the last two years, the AI world has been focused on training.
But the next phase of the market is inference.
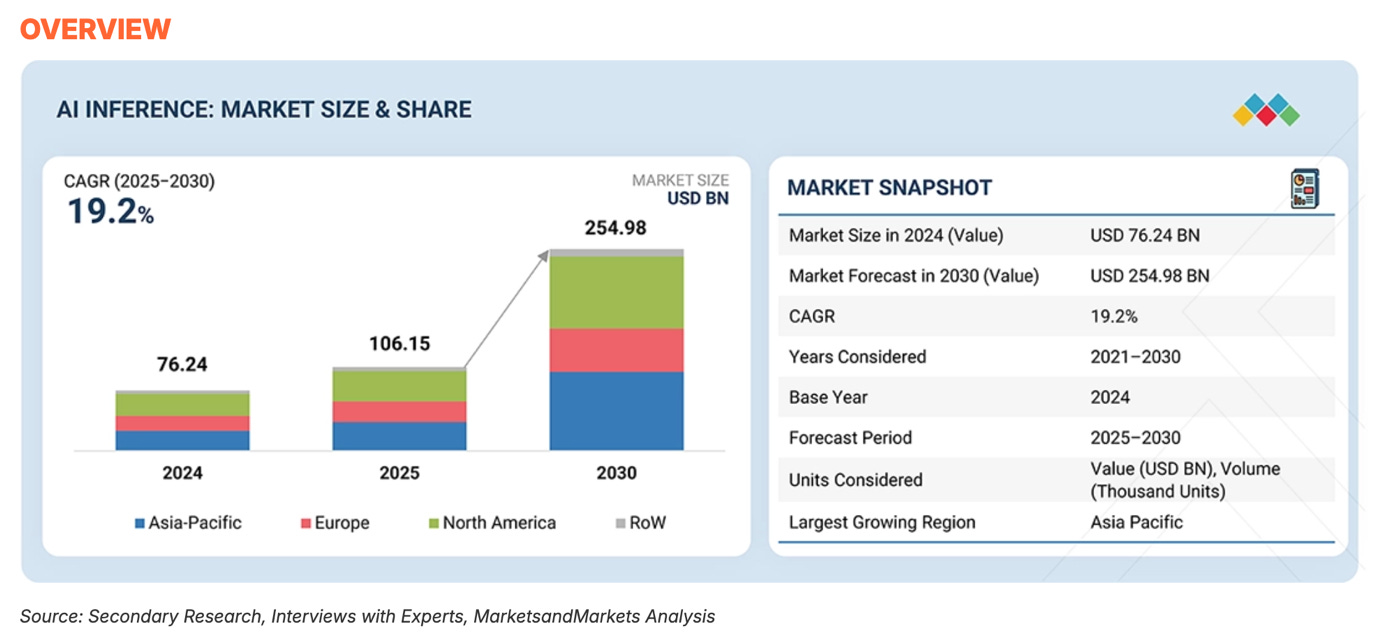
Per Markets and Markets forecast, the AI inference market will grow with a 19.2% CAGR to reach $255B by 2030!
Nebius is working to service this growing demand, but inference is a different kind of business.
While training happens in big bursts, inference happens every second of every day as millions of people use AI apps.
As explored in the Application and Platform layer sections. Nebius has built its Token Factory inference offering.
9.3. Agentic AI
Agentic AI is the next big step after chatbots.
For example, an AI agent could look at your work emails, find a meeting time, book a meeting room, and send you the meeting notes after it.
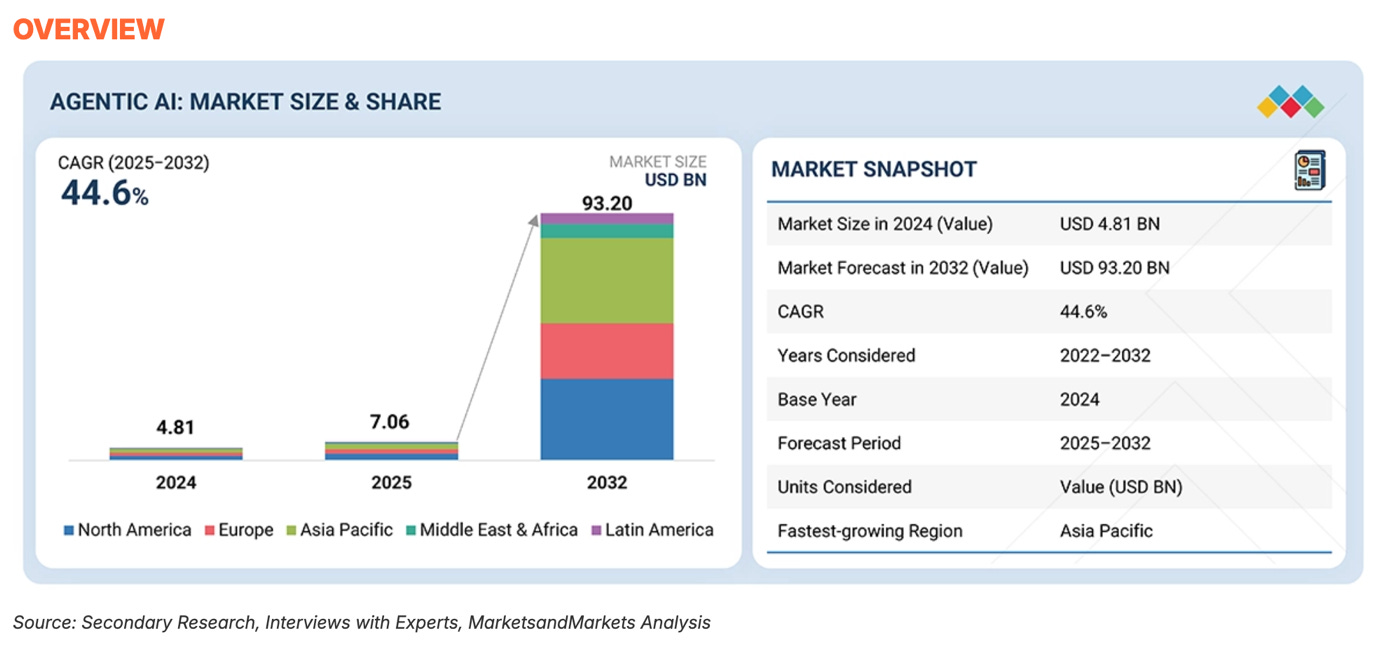
Per Markets and Markets forecast, the Agentic AI market will grow with a 44.6% CAGR to reach $93.2B by 2030!
This is precisely why Nebius acquired Tavily.
As the Agentic AI industry explodes, the need for these agents to have the best and most accurate information will only increase.
Now, not only is Nebius prepared to serve the inference needs of AI Agents, but it can capture the data pipeline needs as well, capturing a larger slice of this market.
10. Valuation
After rising 76% in 2026, Nebius now trades for a market cap of $37.2B!
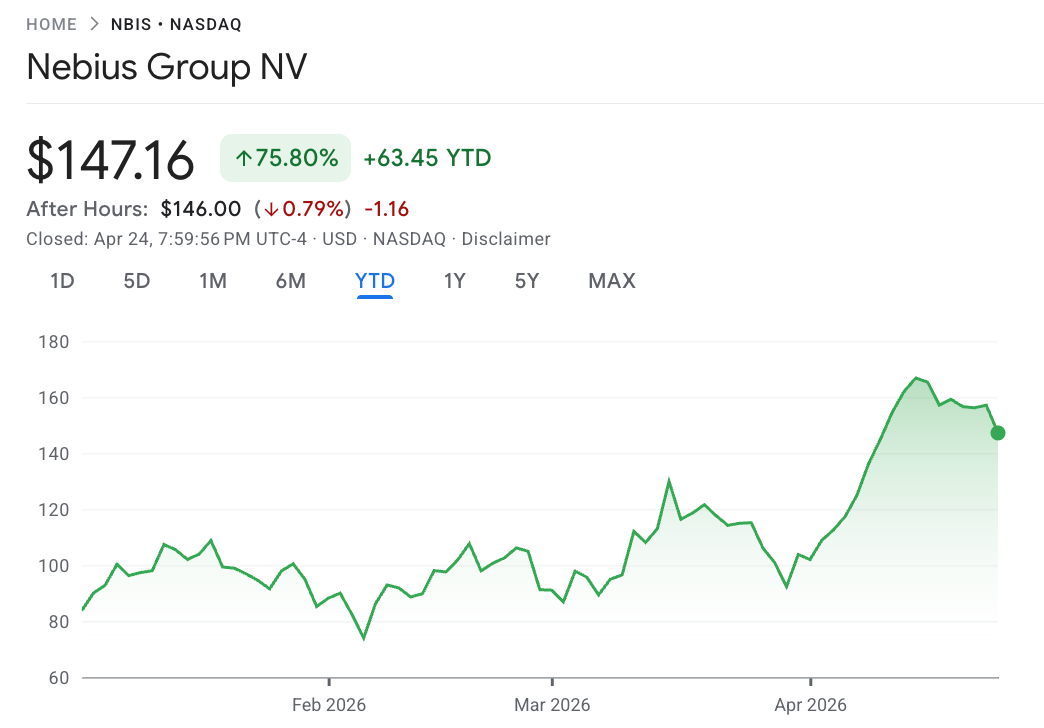
Using the trailing valuation metric is a bit pointless because Nebius gets its value from future potential, not current performance.
At any other company, a P/S of 70 would be insane, but not for Nebius, as they are essentially a start-up.
The only reason Nebius is public in the first place is the unconventional situation with Yandex and its split from Russian assets due to forced selling.
Nebius is essentially a start-up that venture capital investors would normally invest in!
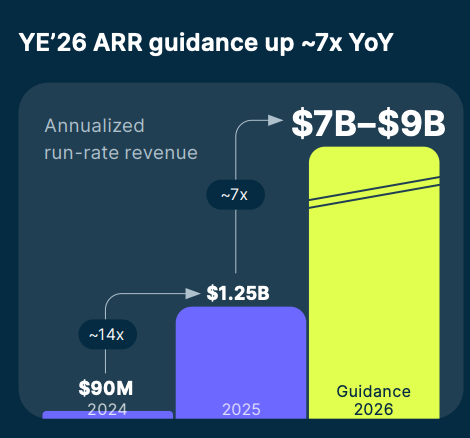
The company expects to close 2026 with an ARR of $7-9B, a 7x Y/Y increase!
This is why Nebius trades 70x 2025 sales.
Incredible growth deserves VC-like revenue multiples.
Taking this guidance into account, Nebius trades for 4-5x 2026 ARR!
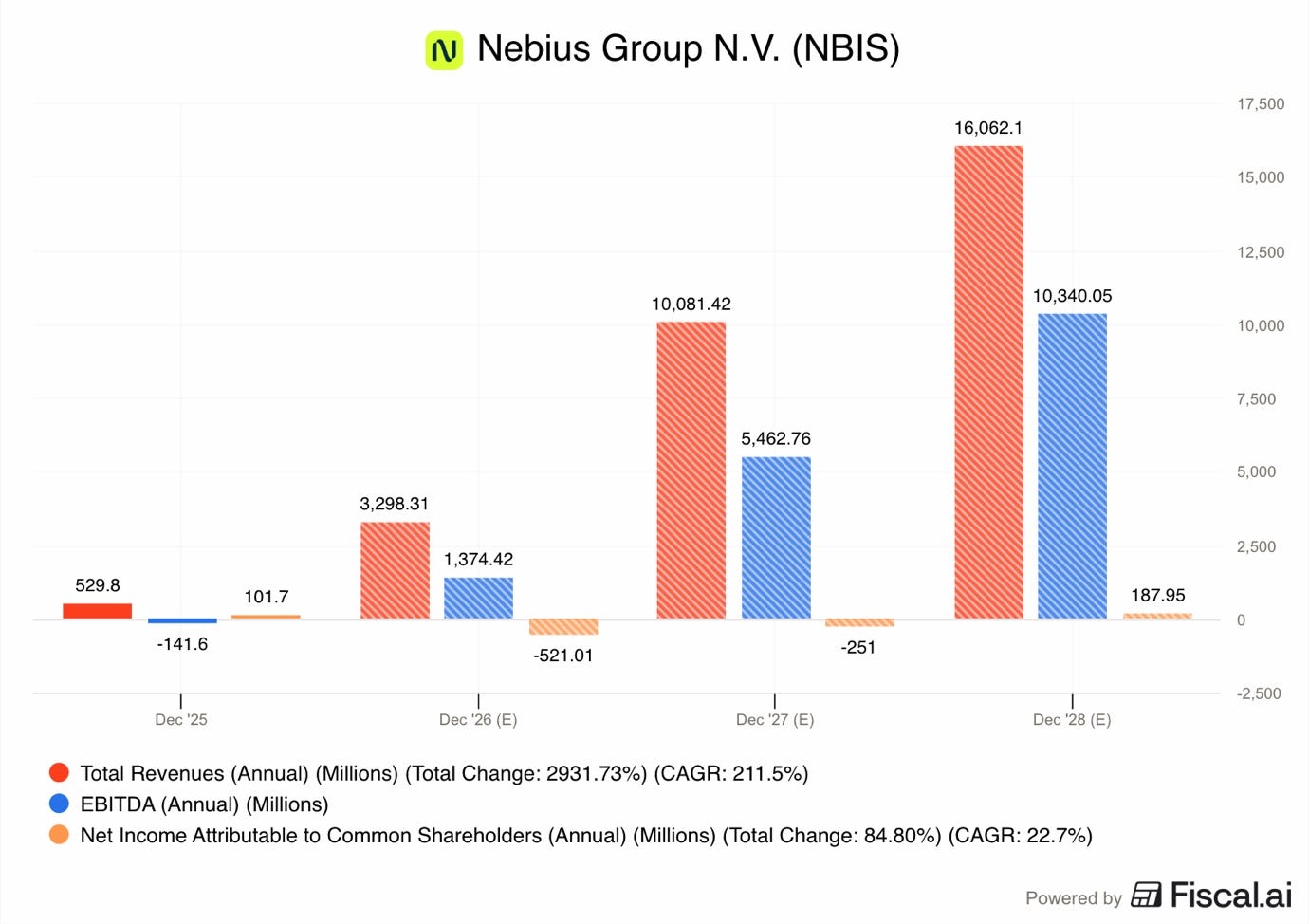
Analysts expect the business to grow revenues by 30x in the next 3 years, reaching $16.1B!
This is absolutely mind-boggling growth, which will come from the company turning on the data centers under construction to begin serving the massive Microsoft and Meta contracts.
At the same time, EBITDA is forecast to reach $10.34B in 2028, compared to the $141.6M loss in 2025.
Taking these analyst consensus 2028 estimates into account, Nebius trades at 2.3x Sales and 3.6x EBITDA.
EBITDA is not the best and final measurement of Nebius profitability as it excludes depreciation and interest, two of the most important expense categories. However, I still view it as an important metric, as it essentially shows the earnings this business is creating from its operations, before looking at what it costs to create that business.
Taking into account depreciation, interest, and taxes, analysts expect 2028 net income to be just $188M. That’s a tiny profit, as the company is still expected to remain in the aggressive growth mode then.
So let’s build a valuation model to try to see what kind of results Nebius could deliver by 2030.
11. Valuation Model
First, Nebius 2026 contracted power target is 3GW, which means that Nebius expects to have agreements with utilities to supply them with 3GW of electricity on 31 December 2026.
Yet, to bring all this capacity online as active IT power, Nebius will need years, as they have to construct the building and install all the electrical, GPUs, cooling, networking, and other equipment.
Thus, I am modelling 3GW of active IT power in 2030.

Next, I estimate that 70% of that capacity will go towards bare metal contracts, largely with Hyperscalers and major start-ups, and 30% as AI cloud to others. The demand that Hyperscalers have for bare metal compute is absolutely insane. I believe Nebius will not miss out on the opportunity to serve them.
This model is also a bit simplified, as I am kind of blending owned and colocation sites together, some of the depreciation expense will probably shift to opex in reality.
For bare metal, I am modeling $9M revenue per MW, whilst for AI cloud, I model $17M.
This would give us bare metal revenues of $18.9B and AI cloud of $15.3B.
Bare metal segment EBITDA of 70% and AI cloud segment EBITDA of 85%.

At $40M per MW, it would cost Nebius to $120B to bring 3GW of capacity online!
While this is an incredibly large amount, I estimate Nebius raising this funding in the following ways:
$40.8B in GPU financing, about 34% of the total amount.
$4.8B in vendor financing, 4% of total
$13.2B in conventional debt, 11% of total.
$25.2B by selling equity.
$21.6B in pre-payments from customers.
$14.4B from internal project cash flow.
So, I model $58.8B of the $120B funding coming from debt at 7% average interest rate!
Banks are open to lending even 90% of the GPU value, so $40.8B sounds completely doable. Also, Nebius just reported $1.56B in cash flow from deferred revenues, and said that they plan to fund the $20B capex for 2026 largely internally.
It is clear that the company is well capitalized, and they have plenty of venues to raise funding from.
Next, to calculate the depreciation, I create a detailed depreciation table.

From total capex, I am modeling 60% going towards GPUs, 19% other equipment, 18% building, and 3% land.
GPUs depreciate in 5 years, other equipment in 7, building in 25, and land never.
The result is 2030 depreciation of $9.83B, and net PPE of $77.7B.
In terms of operating expenses, I model Nebius needing about 14% of revenues to cover R&D and other opex.

We get 2030 revenues of $34.2B, and group EBITDA of $21.45B.
A 63% EBITDA margin might seem high, but we need to remember that for a high-capex data center business such as Nebius, depreciation is the biggest expense.
After taking into account $9.8B depreciation and $4.1B in interest, we get to earnings before taxes of $7.5B.
Tax of 20%.
The result is net income of $6B, a margin of 17.5%.

Next, I model dilution of 45% over the next 5 years, with the total number of shares outstanding reaching 367.1M.
An exit multiple of 30, and we get a $490 stock, an upside of 236% from today’s price of $146.
Discounting back 5 years with a 18% discount rate, we get an estimated fair value per share of $214.34, implying that Nebius share price of $146 could be trading for a 32% discount to its fair value per share.
However, the market would very likely assign a higher multiple to an AI stock such as this if the company delivers the modelled results.
A P/E of 40-50 results in an upside of 348-460%!
I realize that these are very aggressive assumptions, so let’s look at what could go wrong.
1. Demand is not as high as Nebius, McKinsey, Brookfield, and all other experts think. If AI compute supply is higher than the demand, prices could plummet.
2. Competition increases, driving down prices and lowering ARR.
3. There is a lot of debate regarding the 4-6 year depreciation schedule, with many arguing that chip useful lives are much lower. In such a scenario, the deprecation cost of 5 years I modeled could be much higher.
4. Some analysts have voiced concerns regarding the electricity prices. We are entering a stage of AI development where energy access is a key bottleneck, and AI demand might lead to significantly higher prices, possibly leading to lower segment EBITDA margins.
5. Growth could stall if Nebius can’t raise the capital required. Currently, that seems unlikely, but things could change quickly.
6. Geopolitical and trade issues could cause disruptions in the semiconductor supply chain, delaying crucial chip deliveries. If Asian countries that manufacture the data center equipment suffer an energy crisis because of the Iran war, they might be forced to increase prices.
7. OpenAI is the driving force behind the AI revolution. It is very likely that Nebius’ New Jersey capacity sold to Microsoft will go to OpenAI. Recently, they have been signing deals left and right with Nvidia, Oracle, AMD, Broadcom, Corewave, and many more, totaling over $1T. Some have raised concerns of a bubble forming, if they are right, the bursting of this bubble could prove to be catastrophic to Nebius.
However, despite these risks, the revolutionary potential that AI has, and the strong drive and statements from everyone in the AI ecosystem, lead me to believe that Nebius is an incredible opportunity.
Even if costs are much higher than I model, the top-line growth is incredibly impressive!
At P/S of 8, Nebius could be a $200B company in 2030.
12. Conclusion
In conclusion, Nebius AI Cloud and AI refinery business is uniquely positioned for an absolutely mindboggling growth in the next decade!
The recent deals with Microsoft and Meta elevate their pedigree in the eyes of investors, bankers, employees, AI start-ups, other Hyperscalers, and other participants of the AI ecosystem.
As Brookfield pointed out, the AI demand is forecasted to grow 11X in the next decade, making AI Cloud services one of the fastest-growing industries on the planet. Nebius has all that it takes to become a meaningful player.
The company will have 3GW of contracted power by the end of 2026. It could be that my active IT power estimate for 2030 is conservative.
As the valuation model showed, Nebius could be situated to generate over $30B in revenues past 2030. If my estimates regarding segment margins, interest costs, operating expenses, and depreciation are close, we could be looking at a company printing close to $5B in profits.
In such a scenario, Nebius could become a near $200B company, more than 5x from today!

Here is what my Premium Members can expect:
Portfolio Review - Each month, I will present the portfolio performance and discuss my stock watchlist and my best ideas.
Recent developments.
Unwarranted pullbacks.
Insider activity.
Potential catalysts.
Deep Dives – 8,000+ word detailed analysis of a company, delivered in 3 Parts.
Part 1 – Brief History of the company and its Business Model.
Part 2 – Management, Moats, Competitors, and Risks.
Part 3 – Opportunities, Financial Analysis, and a Valuation Model.
You can expect a comprehensive research report that is educational, interesting, and provides actionable insights!
To see what you can expect, read my Palantir Deep Dive!
Members of the Premium service get access to my library of 12 Deep Dives and to all future Deep Dives, which will be released on semi-monthly basis.
Investment Cases – A short, concise report with actionable insights.
This report is about the size of a single part of a Deep Dive.
Focused Investment Thesis
Main drivers of the Bull Case
Valuation Model
To see what you can expect, read my Oscar Health Investment Case!
Earnings Reviews and Updates – For companies that are of great interest to me and my readers, I will provide regular quarterly or semi-annual updates after earnings reports.
Financial performance
Business Update
New developments
Updated Valuation Model
To see what you can expect, read my Google Q2 2025 Earnings Review!
Equity Research Report List
You can follow me on Social Media below:
X(Twitter): TheRayMyers
Threads: @global_equity_briefing
LinkedIn: TheRayMyers
Disclaimer: Global Equity Briefing by Ray Myers
The information provided in the “Global Equity Briefing” newsletter is for informational purposes only and does not constitute financial advice, investment recommendations, or an offer or solicitation to buy or sell any securities. Ray Myers, as the author, is not a registered financial advisor, and readers should consult with their own financial advisors before making any investment decisions.
The content presented in this newsletter is based on publicly available information and sources believed to be reliable. However, Ray Myers does not guarantee the accuracy, completeness, or timeliness of the information provided. The author assumes no responsibility or liability for any errors or omissions in the content or for any actions taken in reliance on the information presented.
Readers should be aware that investing involves risks, and past performance is not indicative of future results. The author may or may not hold positions in the companies mentioned in the “Global Equity Briefing” report. Any investment decisions made based on the information in this newsletter are at the sole discretion of the reader, and they assume full responsibility for their own investment activities.
The AWS of AI framing is everywhere right now, but the Cast AI stat about 95% of chips sitting idle in enterprise deployments is the one number in this piece worth arguing about. The Microsoft and Meta contracts are real revenue, but the question is whether those anchor clients represent the leading edge of demand or the full picture of it.
Really appreciate this deep dive. Great work!